人脸识别的原理到底是什么?
来源:
奇酷教育 发表于:
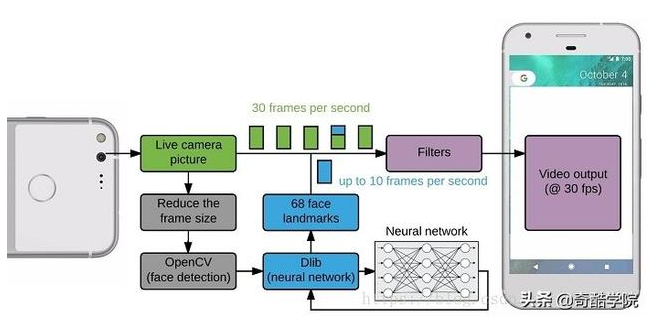
人脸识别流程。
我们知道人脸识别在这几年应用相当广泛,人脸考勤,人脸社交,人脸支付,哪里都有这黑科技的影响,特别这几年机器学习流行,使得人脸识别在应用和准确率更是达到了一个较高的水准。
1、人脸识别流程
人脸识别是由一系列的几个相关问题组成的:
首先找到一张图片中的所有人脸。
对于每一张脸来说,无论光线明暗或面朝别处,它依旧能够识别出是同一个人的脸。
能够在每一张脸上找出可用于他人区分的独特之处,比如眼睛多大,脸有多长等等。
最后将这张脸的特点与已知所有人脸进行比较,以确定这个人是谁。
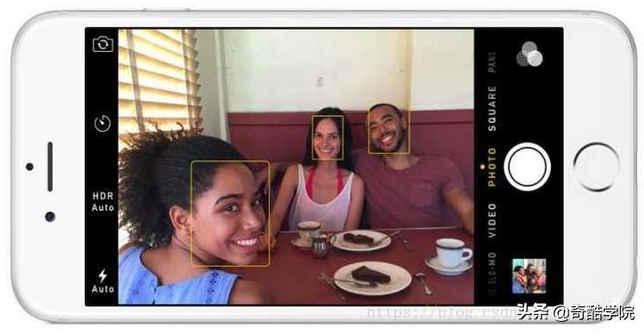
第一步:找出所有的面孔
很显然在我们在人脸识别的流程中得首先找到图片中的人脸。我们在使用手机或相机拍照时都会有人像模式,它能轻松的检测出人脸的位置,帮助相机快速对焦。
人脸识别的原理到底是什么?看完这篇文章你就知道!
我们得感谢 保罗·比奥拉(Paul Viola)和迈克尔·琼斯(Michael Jones)在2000年发明了一种能够快速在廉价相机上运行的人脸检测方法,人脸检测在相机上的应用才成为主流。然而现在我们有更可靠的解决方案HOG(Histogram of Oriented Gradients)方向梯度直方图,一种能够检测物体轮廓的算法。
首先我们把图片灰度化,因为颜色信息对于人脸检测而言没什么用。
人脸识别的原理到底是什么?看完这篇文章你就知道!
我们分析每个像素以及其周围的像素,根据明暗度画一个箭头,箭头的指向代表了像素逐渐变暗的方向,如果我们重复操作每一个像素,最终像素会被箭头取代。这些箭头被称为梯度(gradients),它们能显示出图像从明亮到黑暗流动的过程。
人脸识别的原理到底是什么?看完这篇文章你就知道!
分析每个像素对我们来说有点不划算,因为它太过细节化了,我们可能会迷失在像素的海洋里,我们应该从更高的角度观察明暗的流动。
为此我们将图像分割成16x16像素的小方块。在每个小方块中,计算出每个主方向有多少个剃度(有多少指向上,指向右上,指向右等)。然后用指向性最强的那个方向箭头来代替原来那个小方块。
人脸识别的原理到底是什么?看完这篇文章你就知道!
最终结果,我们把原始图像转换成一个非常简单的HOG表达形式,它可以很轻松的捕获面部的基本结构。
为了在HOG图像中找到脸部,我们需要做的是,与已知的一些HOG图案中,看起来最相似的部分。这些HOG图案都是重其他面部训练数据中提取出来的。
第二步:脸部的不同姿势
我们已经找出了图片中的人脸,那么如何鉴别面朝不同方向的人脸呢?
对于电脑来说朝向不同的人脸是不同的东西,为此我们得适当的调整扭曲图片中的人脸,使得眼睛和嘴总是与被检测者重叠。
为了达到目的我们将使用一种面部特征点估计(face landmark estimation)的算法。其实还有很多算法都可以做到,但我们这次使用的是由瓦希德·卡奇米(Vahid Kazemi)和约瑟菲娜·沙利文(Josephine Sullivan)在 2014 年发明的方法。
这一算法的基本思路是找到68个人脸上普遍存在的点(称为特征点, landmark)。
人脸识别的原理到底是什么?看完这篇文章你就知道!
下巴轮廓17个点 [0-16]
左眉毛5个点 [17-21]
右眉毛5个点 [22-26]
鼻梁4个点 [27-30]
鼻尖5个点 [31-35]
左眼6个点 [36-41]
右眼6个点 [42-47]
外嘴唇12个点 [48-59]
内嘴唇8个点 [60-67]
有了这68个点,我们就可以轻松的知道眼睛和嘴巴在哪儿了,后续我们将图片进行旋转,缩放和错切,使得眼睛和嘴巴尽可能的靠近中心。
现在人脸基本上对齐了,这使得下一步更加准确。
第三步:给脸部编码
我们还有个核心的问题没有解决, 那就是如何区分不同的人脸。
最简单的方法就是把我们第二步中发现的未知人脸与我们已知的人脸作对比。当我们发现未知的面孔与一个以前标注过的面孔看起来相似的时候,就可以认定他们是同一个人。
我们人类能通过眼睛大小,头发颜色等等信息轻松的分辨不同的两张人脸,可是电脑怎么分辨呢?没错,我们得量化它们,测量出他们的不同,那要怎么做呢?
实际上,对于人脸这些信息很容易分辨,可是对于计算机,这些值没什么价值。实际上最准确的方法是让计算机自己找出他要收集的测量值。深度学习比人类更懂得哪些面部测量值比较重要。
所以,解决方案是训练一个深度卷积神经网络,训练让它为脸部生成128个测量值。
每次训练要观察三个不同的脸部图像:
加载一张已知的人的面部训练图像
加载同一个人的另一张照片
加载另外一个人的照片
然后,算法查看它自己为这三个图片生成的测量值。再然后,稍微调整神经网络,以确保第一张和第二张生成的测量值接近,而第二张和第三张生成的测量值略有不同。
我们要不断的调整样本,重复以上步骤百万次,这确实是个巨大的挑战,但是一旦训练完成,它能攻轻松的找出人脸。
庆幸的是 OpenFace 上面的大神已经做完了这些,并且他们发布了几个训练过可以直接使用的网络,我们可以不用部署复杂的机器学习,开箱即用,感谢开源精神。
人脸识别的原理到底是什么?看完这篇文章你就知道!
这128个测量值是什么鬼?
其实我们不用关心,这对我们也不重要。我们关心的是,当看到同一个人的两张不同照片时,我们的网络需要能得到几乎相同的数值。
第四步:从编码中找出人的名字
最后一步实际上是最简单的一步,我们需要做的是找到数据库中与我们的测试图像的测量值最接近的那个人。
如何做呢,我们利用一些现成的数学公式,计算两个128D数值的欧氏距离。
人脸识别的原理到底是什么?看完这篇文章你就知道!
这样我们得到一个欧式距离值,系统将给它一个认为是同一个人欧氏距离的阀值,即超过这个阀值我们就认定他们是 同 (失) 一 (散) 个 (兄) 人 (弟)。
人脸识别就这样达成啦,来来我们再回顾下流程:
使用HOG找出图片中所有人脸的位置。
计算出人脸的68个特征点并适当的调整人脸位置,对齐人脸。
把上一步得到的面部图像放入神经网络,得到128个特征测量值,并保存它们。
与我们以前保存过的测量值一并计算欧氏距离,得到欧氏距离值,比较数值大小,即可得到是否同一个人。
2、人脸识别应用场景
人脸识别分两大步骤,人脸检测和人脸识别,它们应用场景也各不相同。
人脸识别的原理到底是什么?看完这篇文章你就知道!
人脸检测目的是找出人脸,得到人脸的位置,我们可以在美颜,换肤,抠图,换脸 的一些场景中使用到它。我们可以通过系统API调用相机完成对预览针的实时渲染,那些看上去的黑科技我们也可以玩啦。